










Database Replication là một khái niệm không quá mới, nhất là đối với những người làm việc trong lĩnh vực IT. Đồng bộ hóa cơ sở dữ liệu đặc biệt thiết thực khi bạn có nhu cầu phân phối dữ liệu trên nhiều vị trí, tối ưu hiệu suất và an toàn dữ liệu. Cùng Nhân Hòa tìm hiểu kỹ hơn về quá trình này, các điểm mạnh và yếu của giải pháp thiết kế hệ thống trong bài viết dưới đây.
Database Replication là gì?
Database Replication (Sao chép cơ sở dữ liệu) là quá trình tạo và duy trì nhiều bản sao của một cơ sở dữ liệu trên nhiều máy chủ khác nhau. Việc này giúp cải thiện hiệu suất, đảm bảo tính sẵn sàng cao và tăng cường khả năng dự phòng dữ liệu trong trường hợp xảy ra sự cố.

>>> XEM THÊM: Hệ quản trị cơ sở dữ liệu là gì? Các hệ quản trị CSDL phổ biến
Lợi ích của Database Replication
Database Replication đóng vai trò quan trọng trong thiết kế hệ thống về hiệu năng, độ tin cậy và tính sẵn sàng cao. Dưới đây là một số lợi ích quan trọng mà quá trình này mang lại:
Tăng tính tin cậy và tính sẵn sàng
Khi một node gặp sự cố do lỗi phần cứng, mã độc hay các vấn đề khác, dữ liệu vẫn có thể được truy cập từ các node khác. Điều này giúp đảm bảo rằng hệ thống luôn duy trì tính sẵn sàng và giảm thiểu thời gian gián đoạn dịch vụ.
Cải thiện hiệu năng
Nhờ vào việc phân chia tải giữa các node, hệ thống có thể xử lý đồng thời nhiều yêu cầu đọc và ghi, giúp giảm tải cho máy chủ chính và cải thiện tốc độ phản hồi của ứng dụng.

Tăng cường hiệu suất Network
Lưu trữ dữ liệu ở nhiều node, đặc biệt là khi các node này được đặt gần với người dùng, giúp giảm độ trễ trong quá trình truyền tải dữ liệu. Điều này mang lại trải nghiệm mượt mà hơn cho người dùng và tối ưu hóa hiệu suất mạng.
Hỗ trợ phân tích dữ liệu
Việc nhân bản dữ liệu vào một kho lưu trữ riêng biệt không chỉ đảm bảo an toàn dữ liệu mà còn tạo điều kiện thuận lợi cho các team phân tích dữ liệu làm việc trên cùng một dự án. Dữ liệu được đồng bộ và sẵn có giúp việc truy xuất, xử lý và phân tích diễn ra nhanh chóng và hiệu quả hơn.
Phân loại Database Replication
Có 3 loại Database Replication phổ biến mà bạn cần biết là: Master-Slave Replication, Master-Master Replication và Multi-Master Replication. Mỗi loại có những đặc điểm phù hợp với các nhu cầu riêng biệt của người dùng.
Leader-Follower Replication
Trong mô hình này, một node được chỉ định làm leader (master/primary) và các node còn lại là follower (replicas/slaves). Khi client gửi yêu cầu ghi dữ liệu, yêu cầu này sẽ được chuyển đến leader, leader ghi dữ liệu vào storage trước, sau đó gửi các thay đổi đến tất cả các follower để cập nhật. Các yêu cầu đọc dữ liệu có thể được phục vụ từ leader hoặc bất kỳ follower nào.
Mô hình này là tính năng built-in của nhiều CSDL quan hệ (PostgreSQL, MySQL, SQL Server) và cũng được áp dụng ở một số CSDL NoSQL như MongoDB, RethinkDB.
Vấn đề có thể xảy ra:
- Nếu leader gặp lỗi, cần phải chuyển đổi một follower thành leader mới và cấu hình lại các client gửi ghi đến leader mới.
- Nếu follower gặp sự cố, nhờ vào log lưu trữ các thay đổi, nó có thể khôi phục và bắt kịp với leader khi kết nối lại.
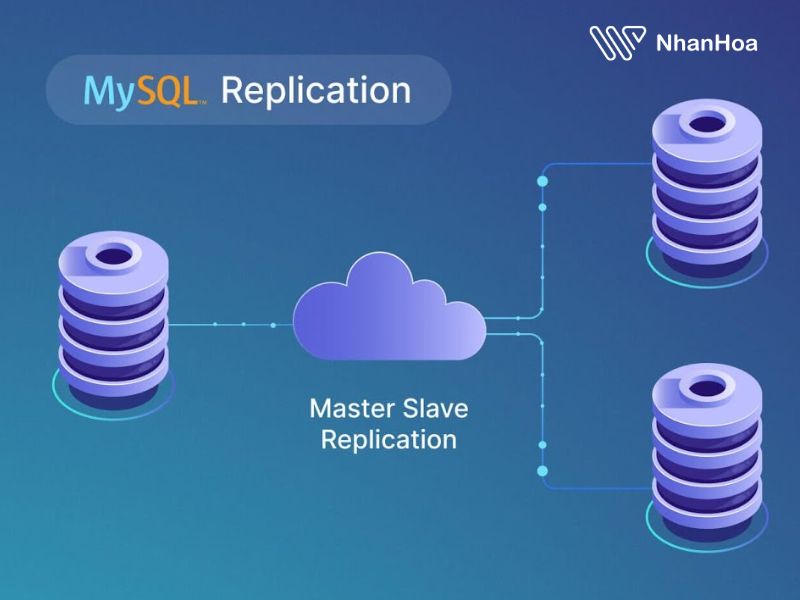
Multi-Leader Replication
Mô hình này được triển khai trên nhiều data center, mỗi data center có một leader riêng. Khi client gửi yêu cầu ghi dữ liệu đến bất kỳ data center nào, leader của data center đó sẽ xử lý yêu cầu và gửi thay đổi đến các follower của mình cũng như đến các data center khác. Điều này giúp giảm thiểu rủi ro do sự cố của một data center và mang lại dữ liệu gần hơn với người dùng.
Use Cases và vấn đề:
- Use Cases: Phù hợp với ứng dụng cần hoạt động offline (ví dụ: ứng dụng lịch) hoặc phối hợp chỉnh sửa thời gian thực (như Google Docs, Etherpad).
- Vấn đề: Mâu thuẫn ghi có thể xảy ra khi nhiều leader xử lý thay đổi dữ liệu cùng lúc, đòi hỏi giải pháp xử lý xung đột dữ liệu hiệu quả.
Leaderless Replication
Trong mô hình leaderless, không có node nào được chỉ định làm leader. Client gửi trực tiếp yêu cầu ghi đến một số replicas khả dụng; những replica này sẽ chấp nhận và ghi dữ liệu. Khi đọc, client gửi yêu cầu đến nhiều replicas cùng lúc để nhận phản hồi, từ đó tự quyết định kết quả hợp nhất.
Vấn đề có thể xảy ra: Nếu một số replicas không khả dụng, không có cơ chế failover rõ ràng. Client có thể nhận được kết quả không đồng nhất nếu chỉ một vài server ghi thành công, điều này làm tăng nguy cơ không đạt được sự nhất quán trong hệ thống.
>>> XEM THÊM: Hướng dẫn cài đặt MySQL chi tiết từng bước
Hạn chế của Database Replication
Độ trễ và gián đoạn dịch vụ
Trong các mô hình replication, đặc biệt là khi sử dụng chế độ bất đồng bộ, dữ liệu không được cập nhật ngay lập tức trên tất cả các bản sao, dẫn đến hiện tượng "eventual consistency". Khi khoảng cách giữa các hệ thống replicate tăng lên, độ trễ trong quá trình truyền dữ liệu cũng tăng, có thể ảnh hưởng đến hiệu năng của ứng dụng.
Ngoài ra, quá trình truyền hoặc sao lưu dữ liệu đôi khi gặp phải gián đoạn dịch vụ do lỗi mạng hoặc sự cố trong quá trình đồng bộ hóa.
Phức tạp trong quá trình triển khai, quản lý
Việc thiết lập và duy trì hệ thống replication đòi hỏi cấu hình đồng bộ phức tạp, nhất là đối với các mô hình Multi-Master. Hơn nữa, khi dữ liệu được lưu trữ tại nhiều địa điểm khác nhau, việc theo dõi và quản lý toàn bộ quá trình replication trở nên khó khăn hơn, đặc biệt khi phải triển khai quy trình backup riêng biệt để đảm bảo sự liên tục và an toàn của dữ liệu.

Yêu cầu về nguồn lực và chi phí
Khi số lượng bản sao dữ liệu tăng lên và dữ liệu được lưu trữ tại nhiều vị trí, chi phí về không gian lưu trữ và tài nguyên tính toán cũng tăng theo. Việc duy trì liên tục các bản sao đòi hỏi lưu lượng mạng cao, từ đó có thể ảnh hưởng đến hiệu suất của các công việc khác trong hệ thống.
Rủi ro mất dữ liệu và vấn đề đồng bộ
Rủi ro mất dữ liệu luôn tồn tại nếu có lỗi xảy ra trong quá trình đồng bộ hóa, đặc biệt với các mô hình asynchronous. Đảm bảo rằng tất cả các bản sao dữ liệu được cập nhật đồng bộ là một thách thức lớn, nhất là khi số lượng nút và khoảng cách địa lý giữa chúng tăng lên. Nếu quá trình đồng bộ bị gián đoạn hoặc gặp sự cố, hệ thống có thể bị mất một phần hoặc toàn bộ dữ liệu, đòi hỏi phải có các biện pháp dự phòng và backup chặt chẽ.
>>> XEM THÊM: Tất tần tật thông tin cần biết về hệ quản trị CSDL redis cache
Cách để chọn loại Replication phù hợp
Để lựa chọn được loại Database Replication phù hợp phụ thuộc vào nhiều yếu tố như mục tiêu sử dụng, tính sẵn sàng, hiệu suất, khả năng mở rộng và tính nhất quán dữ liệu. Dưới đây là một số tiêu chí quan trọng để đưa ra quyết định:
Dựa trên yêu cầu về hiệu năng
Nếu ứng dụng của bạn cần xử lý nhiều yêu cầu đọc và ghi cùng lúc, hãy chọn Multi-Master Replication. Mô hình này cho phép tất cả các máy chủ xử lý cả đọc và ghi, giúp phân tán tải và tăng khả năng mở rộng. Tuy nhiên, nó đòi hỏi phải có cơ chế đồng bộ phức tạp để xử lý xung đột.
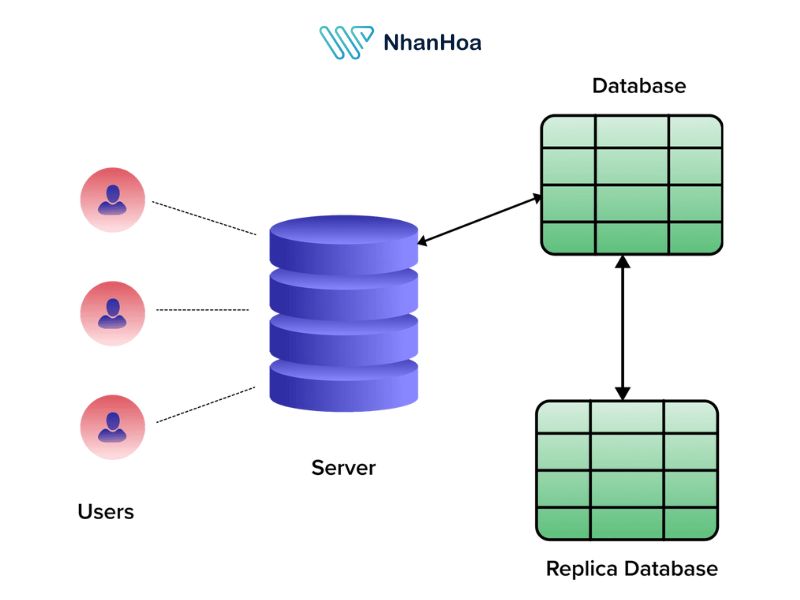
Dựa trên yêu cầu về tính toàn vẹn dữ liệu
Khi tính toàn vẹn dữ liệu là ưu tiên hàng đầu, Master-Slave Replication là lựa chọn lý tưởng. Chỉ có một máy chủ "master" thực hiện ghi, còn các máy chủ "slave" đảm nhận việc đọc. Cách tiếp cận này giảm thiểu khả năng xung đột dữ liệu, đảm bảo mọi thay đổi được kiểm soát từ một nguồn duy nhất.
Dựa trên ngân sách và khả năng quản lý hệ thống
Nếu ngân sách hạn chế hoặc đội ngũ quản lý không đủ chuyên môn, việc triển khai một hệ thống phức tạp như Multi-Master có thể không khả thi.
Trong trường hợp này, Master-Slave Replication sẽ là lựa chọn ưu việt vì cấu hình đơn giản, dễ triển khai và bảo trì, mặc dù có thể không tối ưu hóa hiệu năng đối với các hệ thống có tải ghi cao.
Tổng kết
Database Replication giúp cải thiện hiệu năng, khả năng mở rộng của hệ thống. Tuy nhiên, bên cạnh đó, nó cũng tồn tại những thách thức như độ trễ dữ liệu, chi phí quản lý cao và rủi ro mất dữ liệu nếu đồng bộ không được thực hiện tốt. Vì vậy, việc lựa chọn áp dụng giải pháp replication cần dựa trên đánh giá cẩn trọng giữa lợi ích và hạn chế, nhằm mang lại hiệu quả tối ưu cho hệ thống của bạn.
Thông tin liên hệ Nhân Hòa:
+ Tổng đài: 1900 6680
+ Website: https://nhanhoa.com/
+ Fanpage: https://www.facebook.com/nhanhoacom
+ Khuyến mãi Nhân Hòa: https://nhanhoa.com/khuyen-mai.html



 Phản ánh chất lượng dịch vụ:
Phản ánh chất lượng dịch vụ: 

