










Reinforcement Learning (Học tăng cường) - phương pháp trong trí tuệ nhân tạo, giúp máy tính tự học từ kinh nghiệm bằng cách thử và sai. Nó giống như cách con người học kỹ năng mới trong đời sống hàng ngày, từ đó ra quyết định tối ưu hơn qua thời gian. Cùng Nhân Hòa tìm hiểu chi tiết về RL và cách ứng dụng vào thực tế.
1. Reinforcement Learning là gì?
Reinforcement Learning (RL) là một phương pháp huấn luyện Trí tuệ nhân tạo (AI), trong đó AI tự học cách đưa ra quyết định thông qua quá trình "thử và sai". Nhận phần thưởng khi làm tốt và hình phạt khi làm sai để dần tối ưu hành vi của mình theo thời gian.
Ví dụ: Xe tự lái: AI trong xe học cách giữ khoảng cách an toàn (được thưởng), không vượt đèn đỏ hoặc va chạm (phạt nặng) để lái xe an toàn trên đường.
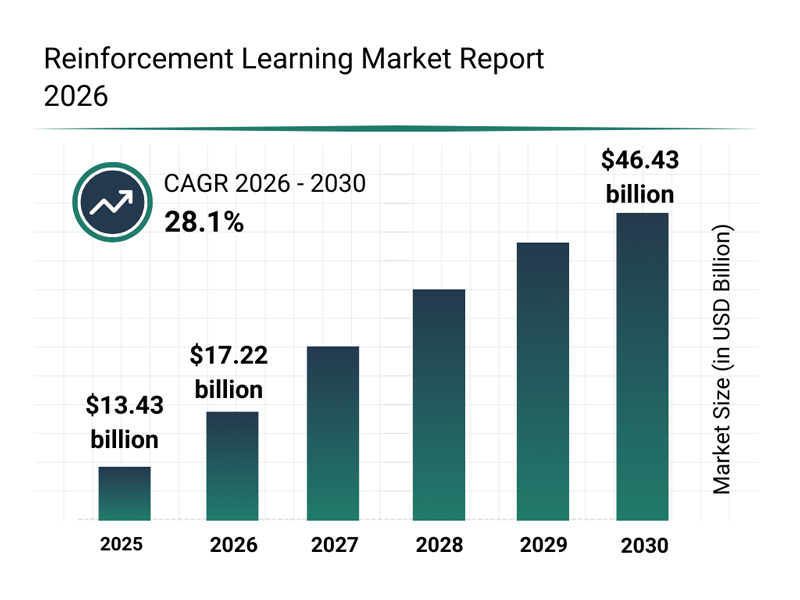
Theo trang The Business Research, hiện nay thị trường Reinforcement Learning toàn cầu được dự báo tăng trưởng mạnh, từ khoảng 14,22 tỷ USD năm 2026 và có thể đạt gần 46,43 tỷ USD vào 2030.
>>> Xem thêm: Deep learning (Học sâu) là gì? Ứng dụng thực tế và xu hướng 2026
2. Các thành phần cốt lõi trong hệ thống Reinforcement Learning
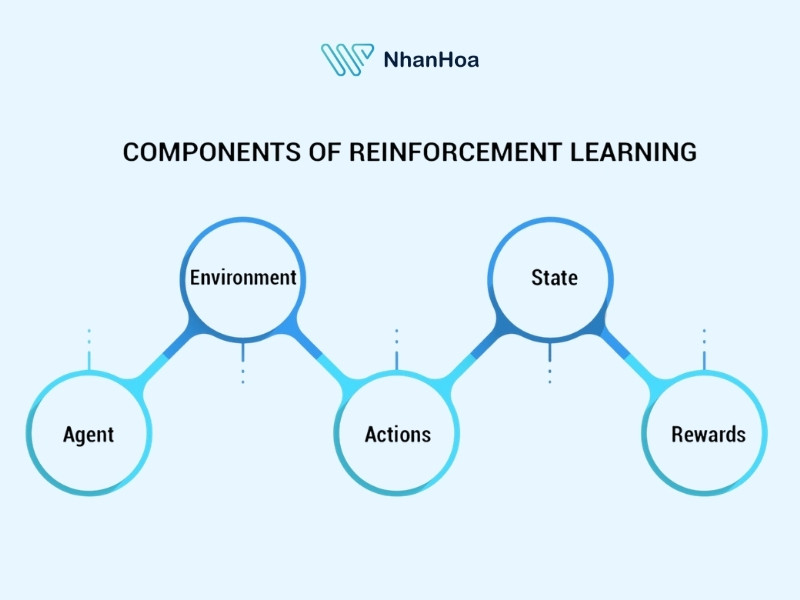
Reinforcement Learning gồm những thành phần trong hệ thống như:
-
Tác tử (Agent): Thuật toán hoặc mô hình ra quyết định.
-
Môi trường (Environment): Không gian mà tác tử tương tác, chứa quy tắc và trạng thái.
-
Trạng thái (State): Tình huống hiện tại của môi trường tại một thời điểm.
-
Hành động (Action): Lựa chọn mà tác tử thực hiện để thay đổi trạng thái.
-
Phần thưởng (Reward): Tín hiệu phản hồi sau mỗi hành động (có thể dương, âm hoặc 0).
-
Phần thưởng tích lũy (Cumulative Reward): Tổng giá trị phần thưởng theo thời gian - mục tiêu tối ưu mà tác tử hướng tới.
3. Cách học tăng cường (reinforcement learning) hoạt động như thế nào?
Reinforcement Learning được xây dựng dựa trên mô hình Markov Decision Process (MDP) - một khuôn khổ toán học mô tả quá trình ra quyết định theo từng bước thời gian.
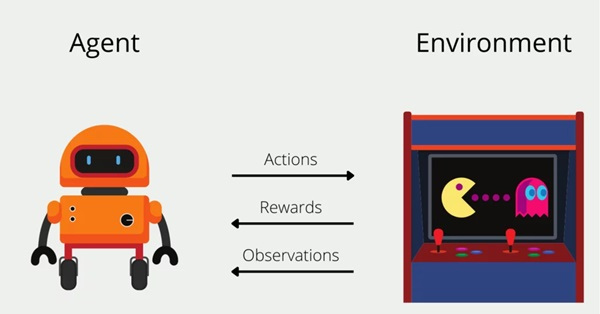
Cơ chế hoạt động có thể hiểu đơn giản như cách con người học qua “thử và sai”: hành động nào mang lại kết quả tốt sẽ được lặp lại, hành động gây kết quả xấu sẽ dần bị loại bỏ.
Quy trình diễn ra theo chu kỳ:
-
Tác tử quan sát trạng thái hiện tại của môi trường.
-
Dựa trên một chính sách (policy), tác tử chọn một hành động.
-
Môi trường cập nhật sang trạng thái mới và trả về phần thưởng tương ứng.
-
Tác tử điều chỉnh chiến lược để tối đa hóa phần thưởng trong dài hạn.
4. Lợi ích và thách thức của Reinforcement Learning là gì?
4.1. Lợi ích nổi bật của học tăng cường
-
Tối ưu mục tiêu dài hạn: Reinforcement Learning (RL) tập trung tối đa hóa phần thưởng tích lũy, giúp cân bằng giữa lợi ích trước mắt và chiến lược lâu dài.
-
Tự học qua tương tác: Không cần dữ liệu gắn nhãn sẵn, tác tử học bằng cách thử - sai trực tiếp với môi trường.
-
Thích nghi tốt: RL có khả năng điều chỉnh khi môi trường thay đổi, điển hình như thành công của AlphaGo do DeepMind phát triển.
4.2. Thách thức
-
Tốn dữ liệu và tài nguyên: Cần rất nhiều lần tương tác để học được chiến lược hiệu quả, đặc biệt trong môi trường có không gian trạng thái rộng.
-
Phần thưởng bị trì hoãn: Kết quả chỉ xuất hiện sau nhiều bước, gây khó khăn cho việc học. Ví dụ như trong cờ vua, người chơi chỉ biết thắng hay thua khi ván đấu kết thúc.
-
Khó giải thích: Quyết định của mô hình thường thiếu tính minh bạch, hạn chế ứng dụng trong lĩnh vực rủi ro cao.

>>> Xem thêm: Hạ tầng cho E-learning - Nền tảng vận hành giáo dục trực tuyến
5. Học tăng cường gồm các thuật toán nào?
5.1. Học tăng cường mô hình
Trong hướng tiếp cận này, tác tử (agent) không chỉ học từ trải nghiệm mà còn tự xây dựng một "bản đồ giả lập" (model) của môi trường. Nó sử dụng mô hình này để tính toán, dự đoán trước kết quả và phần thưởng của các hành động thay vì phải thử sai trực tiếp quá nhiều lần.
5.2. Học tăng cường không mô hình
Đây là phương pháp trong đó tác tử không xây dựng mô hình mô phỏng môi trường. Thay vào đó, nó học trực tiếp bằng cách thử nhiều hành động, quan sát phần thưởng nhận được và dần điều chỉnh chính sách để tối đa hóa lợi ích dài hạn.
Ví dụ: Giống như một kiện tướng cờ vua, họ không cầm quân cờ đi bừa, mà luôn nhẩm tính trước trong đầu 3-4 nước đi của cả mình và đối thủ rồi mới quyết định hạ quân.
6. Có những thuật toán nào trong Reinforcement Learning?
6.1. Thuật toán dựa trên giá trị (Value-Based)
Nhóm này tập trung ước lượng giá trị kỳ vọng (value) của từng trạng thái hoặc cặp trạng thái - hành động, rồi chọn hành động có giá trị cao nhất.
-
Q-Learning: Thuật toán Model-Free và Off-Policy, sử dụng bảng Q (Q-table) để lưu giá trị của từng cặp trạng thái - hành động. Tác tử cập nhật dần giá trị này qua trải nghiệm và chọn hành động có Q cao nhất.
-
Deep Q-Network (DQN): Phiên bản mở rộng của Q-Learning, thay Q-table bằng mạng nơ-ron sâu để xử lý môi trường có không gian trạng thái lớn.
-
SARSA: Thuật toán On-Policy, cập nhật giá trị dựa trên chính hành động mà tác tử thực sự thực hiện. Thường ổn định và an toàn hơn trong môi trường rủi ro.
6.2. Thuật toán dựa trên chính sách (Policy-Based)
Nhóm này không ước lượng giá trị trước mà tối ưu trực tiếp chính sách (policy), tức là xác suất chọn hành động trong từng trạng thái.
Một số thuật toán tiêu biểu:
-
REINFORCE
-
Proximal Policy Optimization (PPO)
-
Trust Region Policy Optimization (TRPO)
-
Actor-Critic
-
Advantage Actor-Critic (A2C)
-
Deep Deterministic Policy Gradient (DDPG)
-
Twin Delayed DDPG (TD3)
Góc nhìn chuyên gia từ Nhân Hòa:
Góc nhìn chuyên gia từ Nhân Hòa:
Việc triển khai các thuật toán như Deep Q-Network hay PPO đòi hỏi năng lực tính toán cực lớn. Quá trình "thử và sai" hàng triệu lần của Agent yêu cầu hệ thống phải xử lý song song lượng dữ liệu khổng lồ. Do đó, hạ tầng Máy chủ vật lý hoặc Cloud GPU hiệu năng cao là yếu tố bắt buộc để giảm thời gian huấn luyện từ vài tháng xuống còn vài ngày."
7. Ứng dụng của Reinforcement Learning trong thực tế
Nhờ khả năng học từ trải nghiệm và tối ưu quyết định theo thời gian, Reinforcement Learning (RL) đang được ứng dụng rộng rãi trong nhiều lĩnh vực đòi hỏi độ chính xác và khả năng thích nghi cao.
-
Robot và Xe tự hành:
-
Điều khiển robot: RL giúp robot học cách cầm nắm, di chuyển, lắp ráp linh hoạt trong nhà máy.
-
Xe tự hành: Hỗ trợ tối ưu lộ trình, xử lý tình huống giao thông phức tạp và tiết kiệm nhiên liệu.
-
-
Y tế và Dược phẩm:
-
Tối ưu phác đồ điều trị: Hỗ trợ xây dựng kế hoạch điều trị cá nhân hóa (ung thư, bệnh mãn tính…).
-
Phát triển thuốc: Mô phỏng phản ứng phân tử để rút ngắn thời gian nghiên cứu dược phẩm.
-
-
Tài chính và Đầu tư
-
Giao dịch tự động: Ví dụ hệ thống LOXM của J.P. Morgan sử dụng RL để tối ưu hóa giao dịch.
-
Quản lý danh mục: Cân bằng lợi nhuận - rủi ro theo biến động thị trường.
-
-
Sản xuất và Bảo trì:
-
Tối ưu dây chuyền: Điều chỉnh thông số vận hành để tăng hiệu suất, giảm lãng phí.
-
Bảo trì dự đoán: Phân tích dữ liệu máy móc để phát hiện lỗi sớm.
-
-
Trò chơi và Mô phỏng
-
AI chơi game: Như AlphaGo đánh bại nhà vô địch cờ vây thế giới.
-
Mô phỏng thực tế ảo: Tạo môi trường huấn luyện AI và nghiên cứu hành vi.
-

>>> Những bài viết liên quan:
Lời kết
Reinforcement Learning đang trở thành nền tảng quan trọng trong việc tối ưu các hệ thống thông minh nhờ khả năng học từ trải nghiệm. Dù còn nhiều thách thức, công nghệ này đã chứng minh hiệu quả trong nhiều lĩnh vực thực tế. Trong tương lai, nó hứa hẹn sẽ tiếp tục thúc đẩy sự phát triển của trí tuệ nhân tạo hiện đại.


.jpg)

 Phản ánh chất lượng dịch vụ:
Phản ánh chất lượng dịch vụ: 

