










Trong Machine Learning, Learning Rate (tốc độ học) là một tham số giúp mô hình quyết định “học nhanh hay chậm” từ dữ liệu. Vậy làm sao để điều chỉnh tốc độ này hợp lý? Bài viết dưới đây của Nhân Hòa sẽ giúp bạn hiểu rõ Learning Rate và 4 phương pháp tối ưu quan trọng.
1. Learning Rate là gì?
Learning Rate (Tốc độ học) là một siêu tham số (hyperparameter) quan trọng bậc nhất trong Machine Learning và Deep Learning. Nó quyết định kích thước bước mà mô hình thực hiện để cập nhật trọng số (weights) nhằm tìm ra điểm tối ưu (giá trị hàm mất mát nhỏ nhất).

Lựa chọn giá trị learning rate có tầm quan trọng sống còn đến sự thành bại của quá trình huấn luyện. Nếu learning rate quá lớn, mô hình sẽ dao động dữ dội hoặc phân kỳ, không thể học được (không hội tụ). Ngược lại, nếu learning rate quá nhỏ, quá trình học diễn ra chậm chạp, dễ mắc kẹt ở điểm tối ưu cục bộ và tốn nhiều thời gian.
>>> Kiến thức bạn cần biết thêm:
Công thức cập nhật trọng số cơ bản:
>>> Xem thêm: Trợ lý ảo là gì? Top 6+ Virtual Assistant nổi bật nhất
2. Vai trò của Learning Rate trong Machine Learning
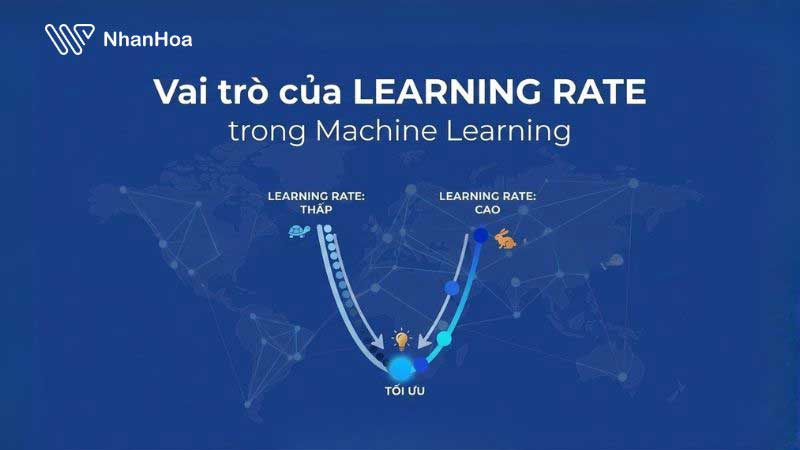
Learning Rate ảnh hưởng trực tiếp đến hội tụ, tốc độ và độ chính xác của mô hình. Cụ thể:
2.1. Điều khiển tốc độ học
Learning Rate quyết định mức độ thay đổi của trọng số sau mỗi lần cập nhật. Giá trị lớn giúp học nhanh nhưng dễ mất ổn định, giá trị nhỏ giúp học chậm nhưng chính xác và ổn định hơn.
2.2. Đảm bảo sự hội tụ của mô hình
Learning Rate ảnh hưởng trực tiếp đến khả năng hội tụ về điểm tối ưu. Nếu quá lớn, mô hình dao động hoặc phân kỳ; nếu quá nhỏ, mô hình hội tụ rất chậm hoặc mắc kẹt tại điểm cực trị cục bộ.
2.3. Cân bằng giữa tốc độ và độ chính xác
Learning Rate tạo ra sự đánh đổi (trade-off) giữa tốc độ huấn luyện và chất lượng mô hình. Giá trị cao ưu tiên tốc độ, giá trị thấp ưu tiên độ chính xác nhưng có nguy cơ underfitting hoặc overfitting.
2.4. Hỗ trợ thoát khỏi điểm cực trị cục bộ
Learning Rate lớn giúp mô hình có đủ "động lượng" để vượt qua các điểm cực trị cục bộ, tiến tới vùng tối ưu toàn cục tốt hơn. Ngược lại, Learning Rate quá nhỏ dễ khiến mô hình bị kẹt lại.
2.5. Tác động đến khả năng tổng quát hóa
Learning Rate ảnh hưởng đến độ phẳng (flatness) của điểm tối ưu. Giá trị phù hợp giúp mô hình hội tụ tại vùng tối ưu phẳng, từ đó cải thiện khả năng tổng quát hóa trên dữ liệu mới.
2.6. Tương tác với các thành phần trong huấn luyện
Learning Rate không hoạt động độc lập mà kết hợp chặt chẽ với batch size (batch càng lớn thường cần Learning Rate càng lớn), loại optimizer (Adam tự điều chỉnh, SGD cần tinh chỉnh thủ công), và kiến trúc mô hình (mô hình càng sâu càng cần Learning Rate nhỏ để tránh gradient bất ổn).
2.7. Điều phối chiến lược huấn luyện nâng cao
Learning Rate là trung tâm của các chiến lược như warm-up (tăng dần Learning Rate ở đầu quá trình), learning rate scheduling (giảm dần theo lịch trình), hay cyclical learning rate (xoay vòng Learning Rate để khám phá vùng tối ưu tốt hơn).
3. Cách xác định Learning Rate tối ưu
Xác định một learning rate tốt phần lớn là quá trình thử và sai. Không có kỹ thuật khoa học dữ liệu nào có thể đảm bảo tìm được learning rate khởi tạo tối ưu mà không cần đánh giá tiến trình trong quá trình huấn luyện.
Các phương pháp phổ biến để xác định learning rate bao gồm:
- Tìm kiếm lưới (Grid search)
- Lịch trình Learning Rate (Learning rate schedules)
- Learning Rate thích ứng (Adaptive learning rate)
- Tối ưu hóa siêu tham số (Hyperparameter optimization)
Việc tối ưu learning rate dựa nhiều vào các nguyên lý cốt lõi là suy giảm (decay) và động lượng (momentum). Nhiều thư viện deep learning tính toán decay và momentum thay cho người dùng. Một trong những thư viện đó là Keras API mã nguồn mở, được viết bằng Python với khả năng hỗ trợ TensorFlow, JAX và PyTorch.
3.1. Tìm kiếm lưới (Grid search)
Tìm kiếm lưới là một phương pháp vét cạn (brute force) để xác định learning rate. Các nhà khoa học dữ liệu xây dựng một lưới (grid) chứa tất cả các learning rate tiềm năng. Sau đó, mỗi learning rate được thử nghiệm và đánh giá xác thực (validated). Quá trình xác thực kiểm tra mô hình đã huấn luyện trên một bộ dữ liệu mới và tiếp tục cập nhật các siêu tham số (hyperparameters) của nó.
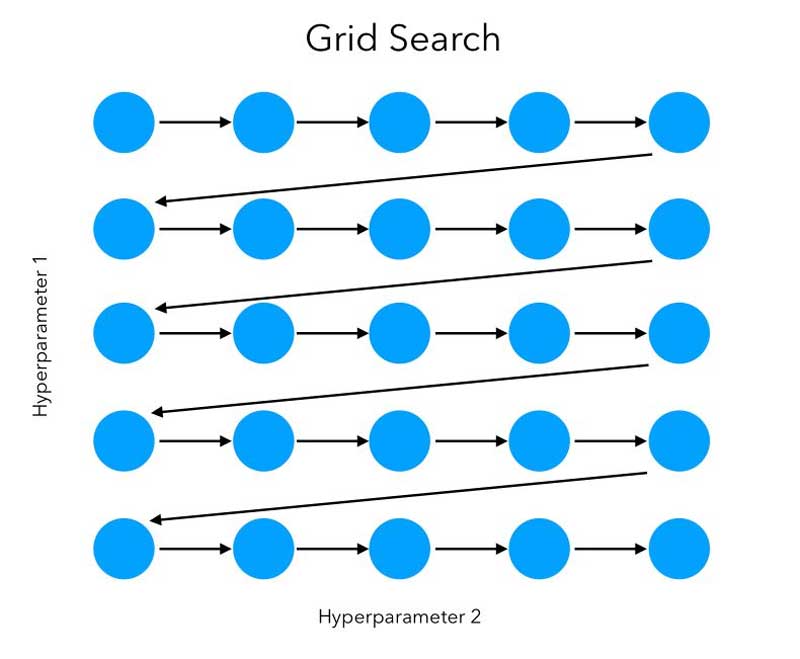
Mặc dù tìm kiếm lưới tạo điều kiện cho quá trình đánh giá learning rate một cách toàn diện, nhưng nó tốn thời gian và ngốn tài nguyên tính toán.
3.2. Lịch trình Learning Rate (Learning rate schedules)
Lịch trình learning rate cập nhật learning rate trong quá trình huấn luyện theo một trong số các kế hoạch được xác định trước. Các lịch trình learning rate phổ biến bao gồm:
- Learning rate cố định (Fixed learning rate)
- Suy giảm theo thời gian (Time-based decay)
- Suy giảm theo bước (Step decay)
- Suy giảm theo cấp số mũ (Exponential decay)
- Suy giảm theo đa thức (Polynomial decay)
- Lịch trình learning rate chu kỳ (Cyclical learning rate schedule)

Learning rate cố định (Fixed learning rate)
Learning rate cố định, hay learning rate hằng số (constant learning rate), không thay đổi trong quá trình huấn luyện. Với learning rate cố định, momentum và decay vẫn giữ nguyên trong suốt quá trình huấn luyện. Learning rate cố định cung cấp một đường cơ sở (baseline) hoặc điểm tham chiếu (reference point) để so sánh với các chiến lược learning rate khác.
Suy giảm theo thời gian (Time-based decay)
Lịch trình suy giảm theo thời gian kích hoạt việc suy giảm learning rate sau một số epoch huấn luyện được xác định trước hoặc tại các epoch cụ thể. Mức độ suy giảm của learning rate dựa trên learning rate của chu kỳ trước. Một lịch trình suy giảm theo thời gian điển hình thường dựa trên hệ số tỷ lệ nghịch (inversely proportional) với số lượng epoch.
Suy giảm theo bước (Step decay)
Suy giảm theo bước giảm learning rate theo một hệ số xác định trước, chẳng hạn như giảm một nửa, sau một số epoch nhất định.
Suy giảm theo cấp số mũ (Exponential decay)
Learning rate suy giảm theo cấp số mũ giảm theo hàm mũ sau một số epoch nhất định. Ngoài điểm khác biệt này, lịch trình suy giảm theo cấp số mũ tương tự như lịch trình suy giảm theo bước.
Suy giảm theo đa thức (Polynomial decay)
Trong lịch trình suy giảm theo đa thức, mức độ suy giảm được xác định bởi hàm đa thức của epoch hiện tại. Nhân epoch với số mũ cao hơn sẽ làm tăng tốc độ suy giảm, trong khi số mũ thấp hơn giúp duy trì tốc độ suy giảm ổn định hơn.
Lịch trình learning rate chu kỳ (Cyclical learning rate schedule)
Lịch trình learning rate chu kỳ xác định giá trị learning rate tối thiểu và tối đa, sau đó dao động (bounce) learning rate giữa hai giá trị này. Lịch trình hình tam giác (triangular schedule) tăng tuyến tính từ giá trị tối thiểu lên tối đa và quay trở lại theo một hằng số xác định. Các lịch trình khác sử dụng các hàm cosine, sinusoidal hoặc parabolic.
3.3. Learning Rate thích ứng (Adaptive learning rate)
Các thuật toán learning rate thích ứng điều chỉnh động (dynamically adjust) dựa trên điều kiện hiện tại hoặc các lần lặp trước đó. Ngược lại, các lịch trình learning rate đều phụ thuộc vào các siêu tham số được xác định trước.
Nhiều phương pháp learning rate thích ứng là các biến thể của SGD (Stochastic Gradient Descent). Các thuật toán learning rate thích ứng đáng chú ý bao gồm:
AdaGrad: Họ thuật toán AdaGrad (adaptive gradient), được giới thiệu vào năm 2011, cập nhật learning rate riêng biệt cho từng tham số. Nó thường thiết lập mối quan hệ tỷ lệ nghịch giữa learning rate và tần suất xuất hiện của đặc trưng (feature frequency). Cách tiếp cận này giúp duy trì sự tập trung vào các đặc trưng quan trọng hơn trong bộ dữ liệu.
- RMSProp: RMSProp (root mean square propagation) điều chỉnh trọng số học (learning weight) cho từng tham số dựa trên trung bình trượt (moving average) của bình phương từng gradient. Nó cải thiện AdaGrad bằng cách bỏ qua các gradient ở quá khứ xa, tăng tính ổn định và dẫn đến hội tụ nhanh hơn.
- Adam: Được giới thiệu vào năm 2014, Adam (adaptive moment estimation) kết hợp momentum với RMSProp để điều chỉnh learning rate của từng tham số dựa trên các gradient trước đó của nó. Các phiên bản sau của Adam đã bổ sung thêm warm start, giúp tăng dần learning rate khi bắt đầu huấn luyện.
3.4. Tối ưu hóa siêu tham số (Hyperparameter optimization)
Tối ưu hóa siêu tham số, hay tinh chỉnh siêu tham số (hyperparameter tuning), là quá trình xác định cấu hình tối ưu cho tất cả các siêu tham số, bao gồm cả learning rate. Các thuật toán tối ưu hóa siêu tham số tự động hóa quá trình cấu hình các siêu tham số tối ưu, mỗi thuật toán ưu tiên một số siêu tham số nhất định hơn các siêu tham số khác.
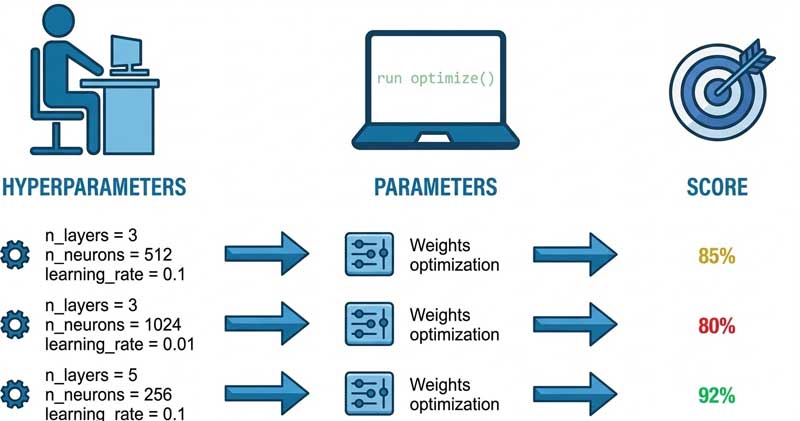
Việc tìm kiếm cấu hình siêu tham số tối ưu tổng thể cho phép xem xét cách thức mà từng siêu tham số ảnh hưởng lẫn nhau. Tuy nhiên, cách tiếp cận này có thể trở nên tốn kém về mặt tính toán, đặc biệt khi có số lượng lớn siêu tham số.
>>> Xem thêm: AI, IoT và Cloud – Bộ ba công nghệ định hình sản xuất thông minh
4. Các chiến lược điều chỉnh Learning Rate
Để tối ưu quá trình huấn luyện, learning rate cần được điều chỉnh phù hợp theo từng giai đoạn. Các chiến lược dưới đây giúp cải thiện tốc độ hội tụ và độ chính xác của mô hình.
4.1. StepLR – Suy giảm theo bước (Step Decay)
StepLR giảm learning rate theo một hệ số cố định sau các khoảng thời gian đều đặn. Trong hình minh họa, nó bắt đầu ở mức 0.1 và giảm một nửa sau mỗi 20 epoch, tạo ra dạng bậc thang đặc trưng mà bạn thấy.
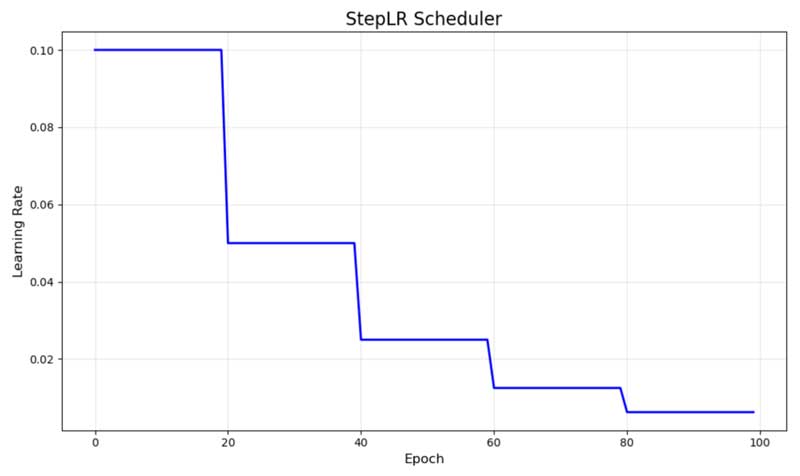
Biểu đồ suy giảm learning rate của StepLR
Lịch trình này hoạt động tốt khi bạn hiểu rõ quá trình huấn luyện của mình và có thể dự đoán thời điểm mô hình cần tập trung vào việc tinh chỉnh (fine-tuning). Nó đặc biệt hữu ích cho các tác vụ phân loại hình ảnh, nơi bạn có thể muốn giảm learning rate sau khi mô hình đã học được các đặc trưng cơ bản.
Ưu điểm chính là tính đơn giản và dễ dự đoán. Tuy nhiên, thời điểm giảm được cố định bất kể tiến trình huấn luyện thực tế, điều này có thể không phải lúc nào cũng tối ưu.
4.2. ExponentialLR – Suy giảm theo cấp số mũ (Exponential Decay)
ExponentialLR giảm learning rate một cách mượt mà bằng cách nhân nó với một hệ số suy giảm mỗi epoch. Ví dụ của chúng tôi sử dụng hệ số nhân 0.95, tạo ra đường cong màu đỏ mượt mà bắt đầu từ 0.1 và dần tiến về 0.
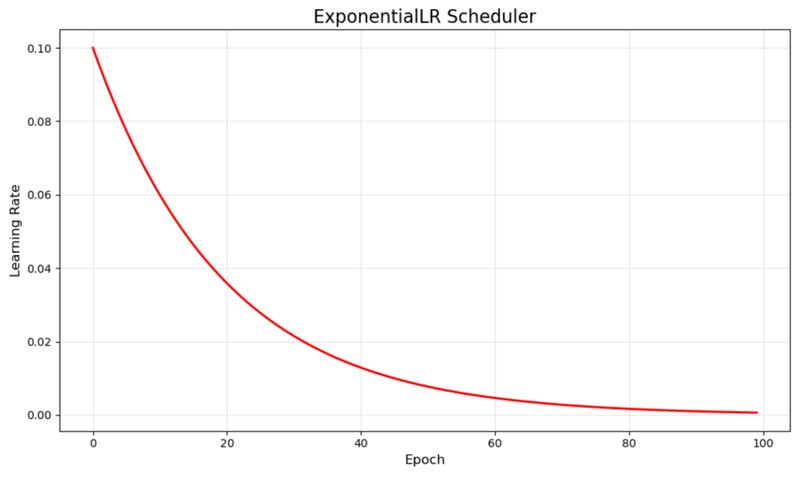
Đường cong suy giảm learning rate của ExponentialLR
Sự suy giảm liên tục này đảm bảo rằng mô hình thực hiện các bước cập nhật ngày càng nhỏ hơn khi quá trình huấn luyện tiến triển. Nó đặc biệt hiệu quả cho các bài toán mà bạn muốn có sự tinh chỉnh dần dần mà không có các chuyển tiếp đột ngột có thể làm gián đoạn đà huấn luyện.
Bản chất mượt mà của suy giảm theo cấp số mũ thường dẫn đến sự hội tụ ổn định, nhưng đòi hỏi phải tinh chỉnh cẩn thận tốc độ suy giảm để tránh giảm learning rate quá nhanh hoặc quá chậm.
4.3. CosineAnnealingLR – Khử nhiệt Cosine (Cosine Annealing)
CosineAnnealingLR tuân theo đường cong cosine, bắt đầu ở mức cao và giảm dần một cách mượt mà đến giá trị tối thiểu. Đường cong màu xanh lá thể hiện sự tiến triển toán học thanh lịch này, vốn tự nhiên làm chậm tốc độ thay đổi khi tiến gần đến giá trị tối thiểu.
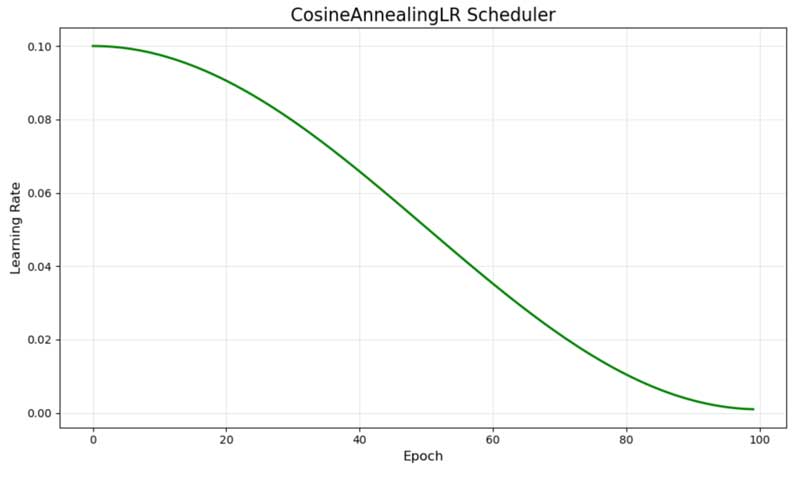
Biểu đồ lịch trình learning rate của CosineAnnealingLR
Lịch trình này được lấy cảm hứng từ khử nhiệt mô phỏng (simulated annealing) và đã trở nên phổ biến trong deep learning hiện đại. Dạng hình cosine cung cấp nhiều thời gian huấn luyện hơn ở mức learning rate cao trong giai đoạn đầu, sau đó dần chuyển sang các pha tinh chỉnh.
Nghiên cứu cho thấy khử nhiệt cosine có thể giúp mô hình thoát khỏi các điểm cực trị cục bộ (local minima) và thường đạt được hiệu suất cuối cùng tốt hơn so với các lịch trình suy giảm tuyến tính, đặc biệt trong các bối cảnh tối ưu hóa phức tạp.
4.4. ReduceLROnPlateau – Giảm thích ứng khi đạt cao nguyên
ReduceLROnPlateau áp dụng một cách tiếp cận khác: nó theo dõi các chỉ số đánh giá trên tập xác thực (validation metrics) và chỉ giảm learning rate khi sự cải thiện bị đình trệ. Hình minh họa màu tím thể hiện hành vi điển hình với các lần giảm xảy ra vào khoảng epoch 25, 50 và 75.
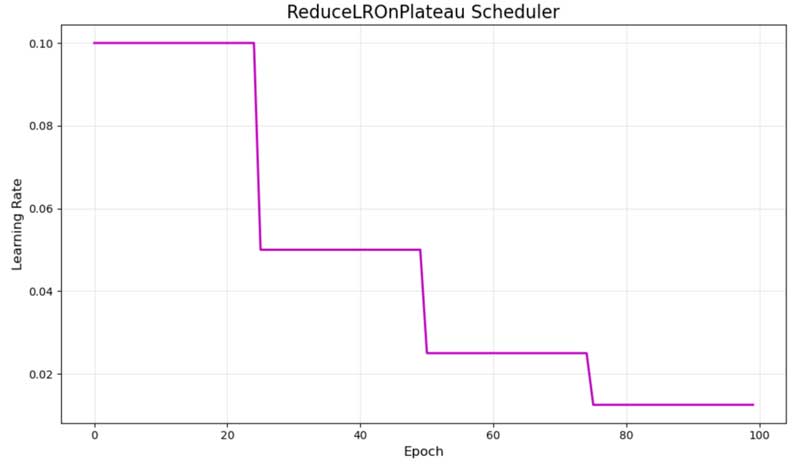
Biểu đồ lịch trình learning rate của ReduceLROnPlateau
Lịch trình thích ứng này phản ứng với tiến trình huấn luyện thực tế thay vì tuân theo một kế hoạch được xác định trước. Nó giảm learning rate khi loss trên tập xác thực ngừng cải thiện trong một số epoch nhất định (tham số patience – tính kiên nhẫn).
Điểm mạnh chính là khả năng phản ứng với diễn biến huấn luyện, khiến nó trở nên xuất sắc trong các trường hợp bạn không chắc chắn về lịch trình tối ưu. Tuy nhiên, nó yêu cầu phải theo dõi các chỉ số xác thực và có thể phản ứng chậm với các điều chỉnh cần thiết.
4.5. CyclicalLR – Learning Rate chu kỳ (Cyclical Learning Rates)
CyclicalLR dao động giữa learning rate tối thiểu và tối đa theo dạng hình tam giác. Hình minh họa màu cam thể hiện các chu kỳ này, với learning rate tăng từ 0.001 lên 0.1 và giảm trở lại trong các chu kỳ 40 epoch.
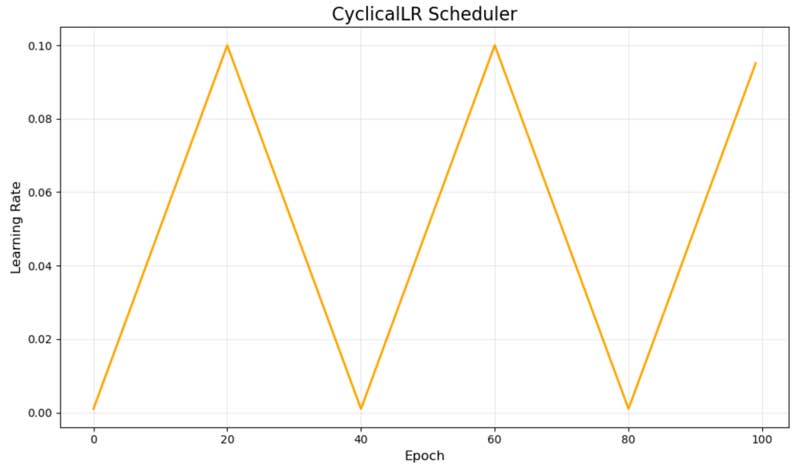
Biểu đồ minh họa dạng learning rate chu kỳ
Cách tiếp cận này, được tiên phong bởi Leslie Smith, thách thức quan niệm truyền thống về việc chỉ giảm learning rate. Lý thuyết cho rằng việc tăng định kỳ giúp mô hình thoát khỏi các điểm cực trị cục bộ kém tối ưu và khám phá bề mặt hàm mất mát hiệu quả hơn.
Mặc dù learning rate chu kỳ có thể đạt được kết quả ấn tượng và thường huấn luyện nhanh hơn các phương pháp truyền thống, nhưng chúng đòi hỏi phải tinh chỉnh cẩn thận các tham số giá trị tối thiểu, giá trị tối đa và độ dài chu kỳ để hoạt động hiệu quả.
5. Ứng dụng Learning Rate thực tế
Không chỉ dùng trong huấn luyện, learning rate còn xuất hiện trong nhiều ứng dụng của Machine Learning và Deep Learning.
- Huấn luyện mô hình học máy (Machine Learning): Learning rate được sử dụng trong các thuật toán tối ưu như Gradient Descent để cập nhật trọng số. Nó giúp mô hình học từ dữ liệu và dần cải thiện độ chính xác qua từng lần lặp.
- Deep Learning và mạng nơ-ron: Trong các mô hình mạng nơ-ron sâu, learning rate ảnh hưởng trực tiếp đến khả năng hội tụ. Việc điều chỉnh phù hợp giúp các mô hình như CNN, RNN hay Transformer học hiệu quả hơn và tránh tình trạng không hội tụ.
- Xử lý ngôn ngữ tự nhiên (NLP): Learning rate được áp dụng trong quá trình huấn luyện các mô hình NLP như dịch máy, chatbot hoặc phân tích cảm xúc. Việc tinh chỉnh learning rate giúp cải thiện độ chính xác trong hiểu và sinh ngôn ngữ.
- Thị giác máy tính (Computer Vision): Trong các bài toán như nhận diện hình ảnh, phát hiện vật thể hoặc phân loại ảnh, learning rate giúp mô hình học nhanh từ dữ liệu lớn và tối ưu hiệu suất nhận diện.
- Tối ưu hóa mô hình (Model Optimization): Learning rate là thành phần cốt lõi trong các thuật toán tối ưu như SGD, Adam, RMSProp. Việc điều chỉnh learning rate giúp cải thiện tốc độ hội tụ và giảm sai số trong quá trình huấn luyện.
- Huấn luyện mô hình trên dữ liệu lớn (Big Data): Với các tập dữ liệu lớn, learning rate giúp kiểm soát tốc độ học, tránh việc cập nhật quá mạnh gây mất ổn định, đồng thời tối ưu thời gian xử lý.
- Transfer Learning (học chuyển giao): Khi fine-tune các mô hình đã được huấn luyện trước, learning rate thường được giảm xuống để tránh phá vỡ các đặc trưng đã học, đồng thời giúp mô hình thích nghi tốt với dữ liệu mới.
- Tự động hóa tối ưu (AutoML): Trong các hệ thống AutoML, learning rate là một trong những siêu tham số quan trọng được tự động điều chỉnh để tìm ra cấu hình tối ưu cho mô hình.
6. [Giải đáp] Các câu hỏi liên quan đến Learning Rate
6.1. Có giá trị learning rate chuẩn không?
Không có một giá trị learning rate cố định áp dụng cho mọi bài toán. Giá trị phù hợp phụ thuộc vào mô hình, dữ liệu và thuật toán tối ưu. Tuy nhiên, các giá trị phổ biến thường nằm trong khoảng 0.001 đến 0.01 và cần được tinh chỉnh thêm trong quá trình huấn luyện.
6.2. Có nên điều chỉnh Learning Rate trong quá trình huấn luyện không?
Có. Việc điều chỉnh learning rate theo từng giai đoạn giúp mô hình học nhanh hơn ban đầu và ổn định hơn khi tiến gần điểm hội tụ, từ đó cải thiện hiệu quả tổng thể.
6.3. Optimizer như Adam có cần Learning Rate không?
Có. Dù Adam có khả năng tự điều chỉnh learning rate cho từng tham số, vẫn cần thiết lập learning rate ban đầu. Việc chọn giá trị phù hợp vẫn ảnh hưởng đến hiệu suất của mô hình.
6.4. Learning rate có phải là siêu tham số quan trọng nhất không?
Learning rate là một trong những siêu tham số quan trọng nhất vì nó ảnh hưởng trực tiếp đến quá trình tối ưu. Tuy nhiên, để đạt hiệu quả tốt nhất, cần kết hợp với các yếu tố khác như batch size, optimizer và kiến trúc mô hình.
>>> Các bài viết liên quan:
- Machine Translation là gì? Lợi ích & ứng dụng nổi bật
- NLU là gì trong AI? Xu hướng tương lai của hệ thống hiểu ngôn ngữ
Lời kết
Không có một Learning Rate “hoàn hảo” cho mọi bài toán, nhưng việc nắm vững 4 cách tính tốc độ học sẽ giúp bạn rút ngắn đáng kể quá trình thử nghiệm. Đây chính là lợi thế quan trọng trong việc xây dựng và tối ưu các mô hình Machine Learning hiện đại.


.jpg)

 Phản ánh chất lượng dịch vụ:
Phản ánh chất lượng dịch vụ: 

